AI Agent工作流实用手册:5种常见模式的实现与应用,助力生产环境稳定性 本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里
AI Agent工作流实用手册:5种常见模式的实现与应用,助力生产环境稳定性
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
智能开放搜索 OpenSearch行业算法版,1GB 20LCU 1个月
本文介绍了五种AI Agent结构化工作流模式,帮助解决传统提示词方式在生产环境中输出不稳定、质量不可控的问题。通过串行链式处理、智能路由、并行处理、编排器-工作器架构和评估器-优化器循环,可提升任务执行效率、资源利用和输出质量,适用于复杂、高要求的AI应用。
很多人认为使用AI Agent就是直接扔个提示词过去,然后等结果。做实验这样是没问题的,但要是想在生产环境稳定输出高质量结果,这套玩法就不行了。
核心问题是这种随意的提示方式根本扩展不了。你会发现输出结果乱七八糟,质量完全不可控,还浪费计算资源。
那些做得好的团队从来不指望一个提示词解决所有问题。他们会把复杂任务拆解成步骤,根据不同输入选择合适的模型,然后持续验证输出质量,直到结果达标。
本文会详细介绍5种常用的的Agent工作流模式,每种都有完整的实现代码和使用场景分析。看完每种模式解决什么问题,什么时候用,以及为什么能产生更好的效果。
链式处理的核心思路是把一个LLM调用的输出直接作为下一个调用的输入。比起把所有逻辑塞进一个巨大的提示词,拆分成小步骤要靠谱得多。
道理很简单:步骤越小,出错的概率越低。链式处理等于给模型提供了明确的推理路径,而不是让它自己瞎猜。
如果不用链式处理,你可能会经常会遇到输出冗长混乱、前后逻辑不一致、错误率偏高的问题。有了链式处理,每一步都可以单独检查,整个流程的可控性会大幅提升。
现实情况是,不是每个查询都需要动用你最强大、最昂贵的模型。简单任务用轻量级模型就够了,复杂任务才需要重型武器。路由机制确保资源分配的合理性。
没有路由的话,要么在简单任务上浪费资源,要么用不合适的模型处理复杂问题导致效果很差。
实现路由需要先定义输入的分类标准,比如简单查询、复杂推理、受限领域等,然后为每个类别指定最适合的模型或处理流程。这样做的好处是成本更低、响应更快、质量更稳定,因为每种任务都有专门的工具来处理。
大部分人习惯让LLM一个任务一个任务地处理。但如果任务之间相互独立,完全可以并行执行然后合并结果,这样既节省时间又能提升输出质量。
并行处理的思路是把大任务分解成可以同时进行的小任务,等所有部分都完成后再把结果整合起来。
比如做代码审查的时候,可以让一个模型专门检查安全问题,另一个关注性能优化,第三个负责代码可读性,最后把所有反馈合并成完整的审查报告。文档分析也是类似的思路:把长报告按章节拆分,每个部分单独总结,再合并成整体摘要。文本分析任务中,情感分析、实体提取、偏见检测可以完全并行进行。
不用并行处理的话,不仅速度慢,还容易让单个模型负担过重,导致输出混乱或者前后不一致。并行方式让每个模型专注于自己擅长的部分,最终结果会更准确,也更容易维护。
这种模式的特点是用一个编排器模型来规划整个任务,然后把具体的子任务分配给不同的工作器模型执行。
编排器的职责是分析任务需求,决定执行顺序,你不需要事先设计好完整的工作流程。工作器模型各自处理分配到的任务,编排器负责把所有输出整合成最终结果。
这种架构在很多场景下都很实用。写博客文章的时候,编排器可以把任务拆分成标题设计、内容大纲、具体章节写作,然后让专门的工作器处理每个部分,最后组装成完整文章。开发程序时,编排器负责分解成环境配置、核心功能实现、测试用例编写等子任务,不同的工作器生成对应的代码片段。数据分析报告也是类似思路:编排器识别出需要数据概览、关键指标计算、趋势分析等部分,工作器分别生成内容,编排器最后整合成完整报告。
这种方式的好处是减少了人工规划的工作量,同时保证复杂任务的有序进行。编排器处理任务管理,每个工作器专注于自己的专业领域,整个流程既有条理又有效率。
具体机制是一个模型负责生成内容,另一个评估器模型按照预设的标准检查输出质量。如果没达标,生成器根据反馈进行修改,评估器再次检查,这个过程一直重复到输出满足要求为止。
在代码生成场景中,生成器写出代码后,评估器会检查语法正确性、算法效率、代码风格等方面,发现问题就要求重写。营销文案也是类似流程:生成器起草内容,评估器检查字数限制、语言风格、信息准确性,不合格就继续改。数据报告的制作过程中,生成器产出分析结果,评估器验证数据完整性和结论的逻辑性。
如果没有这套评估优化机制,输出质量会很不稳定,需要大量人工检查和修正。有了评估器-优化器循环,可以自动保证结果符合预期标准,减少重复的手工干预。
不再是随便抛个提示词然后碰运气,而是有章法地分解任务、合理分配模型资源、并行处理独立子任务、智能编排复杂流程,再通过评估循环保证输出质量。
每种模式都有明确的适用场景,组合使用能让你更高效地处理各种复杂任务。可以先从一个模式开始熟悉,掌握之后再逐步引入其他模式。
当你把路由、编排、并行处理、评估优化这些机制组合起来使用时,就彻底告别了那种混乱、不可预测的提示方式,转而获得稳定、高质量、可用于生产环境的输出结果。长期来看,这种方法不仅节省时间,更重要的是给你对AI系统的完全控制权,让每次输出都在预期范围内,从根本上解决了临时提示方式带来的各种问题。
敬请锁定《C位面对面》,洞察通用计算如何在AI时代持续赋能企业创新,助力业务发展!
敬请锁定《C位面对面》,洞察通用计算如何在AI时代持续赋能企业创新,助力业务发展!
在语音合成技术不断演进的背景下,早期版本的IndexTTS虽然在多场景应用中展现出良好的表现,但在情感表达的细腻度与时长控制的精准性方面仍存在提升空间。为了解决这些问题,并进一步推动零样本语音合成在实际场景中的落地能力,B站语音团队对模型架构与训练策略进行了深度优化,推出了全新一代语音合成模型——IndexTTS2 。
Qwen3-Coder 挑战赛简介:无论你是编程小白还是办公达人,都能通过本教程快速上手 Qwen-Code CLI,利用 AI 轻松实现代码编写、文档处理等任务。内容涵盖 API 配置、CLI 安装及多种实用案例,助你提升效率,体验智能编码的乐趣。
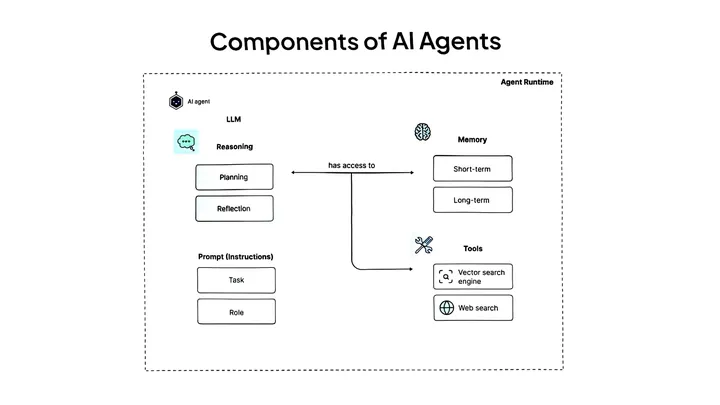
在人工智能浪潮中,智能体(AI Agent)正成为变革性技术。它们具备自主决策、环境感知、任务执行等能力,广泛应用于日常任务与商业流程。本文详解智能体概念、架构及七步搭建指南,助你打造专属智能体,迎接智能自动化新时代。
在 Apache Spark 中利用 HyperLogLog 函数实现高级分析
如何使用Tunnel SDK上传/下载MaxCompute复杂类型数据